1. 自监控实践
本文介绍了,小米公司在 Open-Falcon集群自监控方面 的一些实践。
1.1. 概述
我们把对监控系统的监控,称为监控系统的自监控。自监控的需求,没有超出监控的业务范畴。同其他系统一样,自监控要做好两方面的工作: 故障报警和状态展示。故障报警,要求尽量实时的发现故障、及时的通知负责人,要求高可用性。状态展示,多用于事前预测、事后追查,实时性、可用性要求 较故障报警 低一个量级。下面我们从这两个方面,分别进行介绍。
1.2. 故障报警
故障报警相对简单。我们使用第三方监控组件AntEye,来监控Open-Falcon实例的健康状况。
Open-Falcon各个组件,都会提供一个描述自身服务可用性的自监控接口,描述如下。AntEye服务会定时巡检、主动调用Open-Falcon各实例的自监控接口,如果发现某个实例的接口没有如约返回"ok",就认为这个组件故障了(约定),就通过短信、邮件等方式 通知相应负责人员。为了减少报警通知的频率,AntEye采用了简单的报警退避策略,并会酌情合并一些报警通知的内容。
# API for my availability
接口URL
/health 检测本服务是否正常
请求方法
GET http://$host:$port/health
$host 服务所在机器的名称或IP
$port 服务的http.server监听端口
请求参数
无参数
返回结果(string)
"ok"(没有返回"ok", 则服务不正常)
AntyEye组件主动拉取状态数据,通过本地配置加载监控实例、报警接收人信息、报警通道信息等,这样做,是为了简化报警链路、使故障的发现过程尽量实时&可靠。AntEye组件足够轻量,代码少、功能简单,这样能够保障单个AntEye实例的可用性;同时,AntEye是无状态的,能够部署多套,这进一步保证了自监控服务的高可用。
在同一个重要的网络分区内,通常要部署3+个AntEye,如下图所示。我们一般不会让AntEye做跨网络分区的监控,因为这样会带来很多网络层面的误报。多套部署,会造成报警通知的重复发送,这是高可用的代价;从我们的实践经验来看,这个重复可以接受。
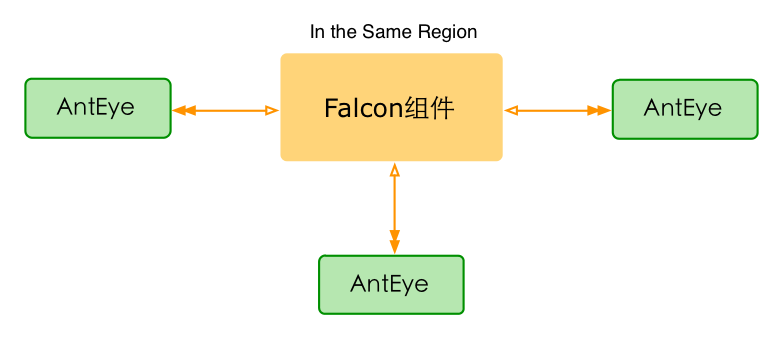
值得注意的是,原来故障发现功能是Open-Falcon的Task组件的一个代码片段。后来,为了满足多套部署的需求,我们把故障发现的逻辑从Task中剔除,转而使用独立的第三方监控组件AntEye。
1.3. 状态展示
状态展示,是将Open-Falcon各组件实例的状态数据,以图形化的形式展示出来,方便人的查看。鉴于实时性、可用性要求不高,我们选择Open-Falcon来做自身状态数据的存储、展示(用Open-Falcon监控Open-Falcon,自举了),剩下的工作就是状态数据的采集了。
Open-Falcon的多数组件,都会提供一个查询服务状态数据的接口,描述如下。
# API for querying my statistics
接口URL
/counter/all 返回所有的状态数据
请求方法
GET http://$host:$port/counter/all
$host 服务所在机器的名称或IP
$port 服务的http.server监听端口
请求参数
无参数
返回结果
// json格式
{
"msg": "success", // "success"表示请求被成功处理,其他均是失败
"data":[ // 自身状态数据的list
// 每个状态数据, 都包含字段 Name(名称)、Cnt(计数)、Time(时间),可能包含字段Qps
{
"Name": "RecvCnt",
"Cnt": 6458396967,
"Qps": 81848,
"Time": "2015-08-19 15:52:08"
},
...
]
}
Open-Falcon的Task组件,通过上述接口,周期性的主动拉取Open-Falcon各实例的状态数据;然后,处理这些状态数据,适配成Open-Falcon要求的数据格式;再将适配后的数据,push给本地的Agent;本地的Agent会将这些数据转发到监控系统Open-Falcon。
Task组件,通过配置文件中的collector项,定义状态数据采集的相关特性,如下
"collector":{
"enable": true,
"destUrl" : "http://127.0.0.1:1988/v1/push", // 适配后的状态数据发送到本地的1988端口(Agent接收器)
"srcUrlFmt" : "http://%s/counter/all", // 状态数据查询接口的Format, %s将被替换为 cluster配置项中的 $hostname:$port
"cluster" : [
// "$module,$hostname:$port",表示: 地址$hostname:$port对应了一个$module服务
// 结合"srcUrlFmt"的配置,可以得到状态数据查询接口 "http://test.host01:6060/counter/all" 等
"transfer,test.host01:6060",
"graph,test.host01:6071",
"task,test.host01:8001"
]
}
Task做数据适配时,将endpoint设置为数据来源的机器名$hostname($hostname为Task采集配置collector.cluster某条记录中的机器名),将metric设置为原始状态数据的$Name和$Name.Qps,将tags设置为module=$module,port=$port,type=statistics,pdl=falcon($module,$port为Task采集配置collector.cluster某条记录中的模块名和端口,其他两项为固定填充), 将数据类型设置为GAUGE,将周期设置为Task的数据采集周期。比如,采用了上述采集配置的Task,将会做如下适配:
# 一条原始的状态数据,来自"transfer,test.host01:6060"
{
"Name": "RecvCnt",
"Cnt": 6458396967,
"Qps": 81848,
"Time": "2015-08-19 15:52:08"
}
# Task适配之后,得到两条监控数据
{
"endpoint": "test.host01", // Task配置collector.cluster中的配置项"transfer,test.host01:6060"中的机器名
"metric": "RecvCnt", // 原始状态数据中的$Name
"value": 6458396967, // 原始状态数据中的$Cnt
"type": "GAUGE", // 固定为GAUGE
"step": 60, // Task的数据采集周期, 默认为60s
"tags": "module=transfer,port=6060,pdl=falcon,type=statistics", // 前两个对应于Task的collector.cluster配置项"transfer,test.host01:6060"中的模块名和端口,后两个是固定填充
...
},
{
"endpoint": "test.host01",
"metric": "RecvCnt.Qps", // 原始状态数据中的$Name + ".Qps"
"value": 81848, // 原始状态数据中的$Qps
"type": "GAUGE",
"step": 60,
"tags": "module=transfer,port=6060,pdl=falcon,type=statistics",
...
}
我们只能向监控系统Open-Falcon,push一份状态数据(push多份会有重叠、不利于观察),因此,在每个网络分区中只能部署一个Task实例(同样地,不建议跨网络分区采集状态数据)。单点部署,可用性太差了吧?确实。不过好在,AntEye服务会监控Task的状态,能够及时发现Task的故障,在一定程度上可以缓解 状态数据采集服务 的单点风险。
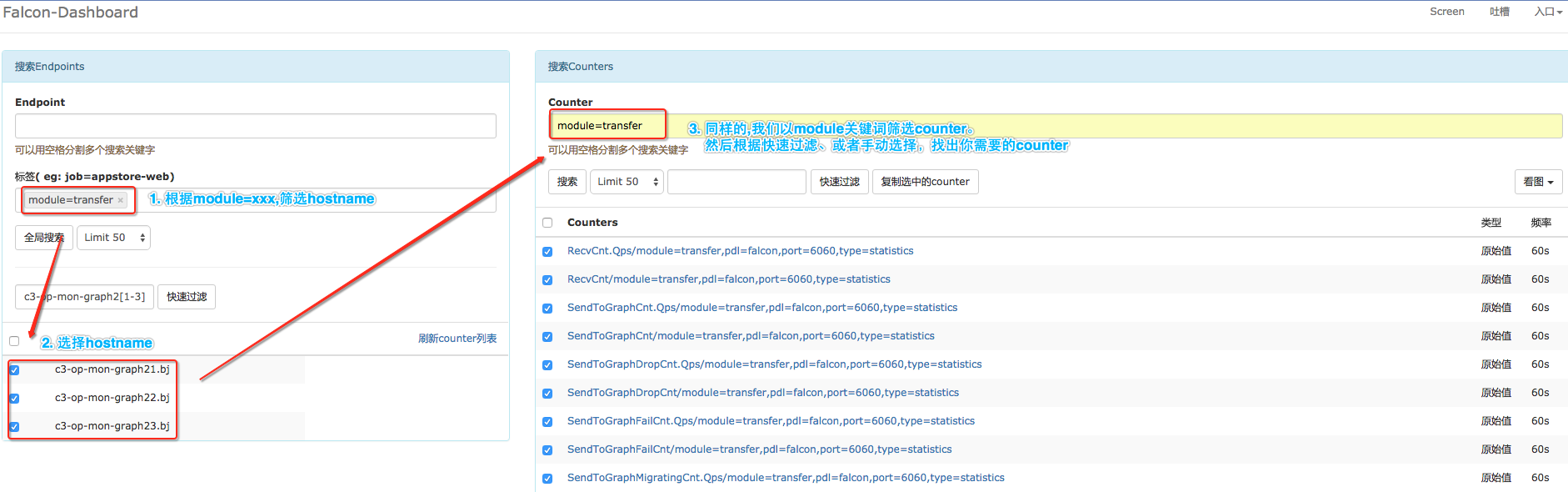
状态数据入Open-Falcon之后,我们就可以定制Screen页面。如下图,是小米Open-Falcon的状态数据统计页面。定制页面时,需要先找到您关注的counter,这个可以通过dashboard进行搜索,如下图。不同组件的自监控counter,具体见附录。
筛选自监控相关的状态指标
定制你的自监控状态数据Screen
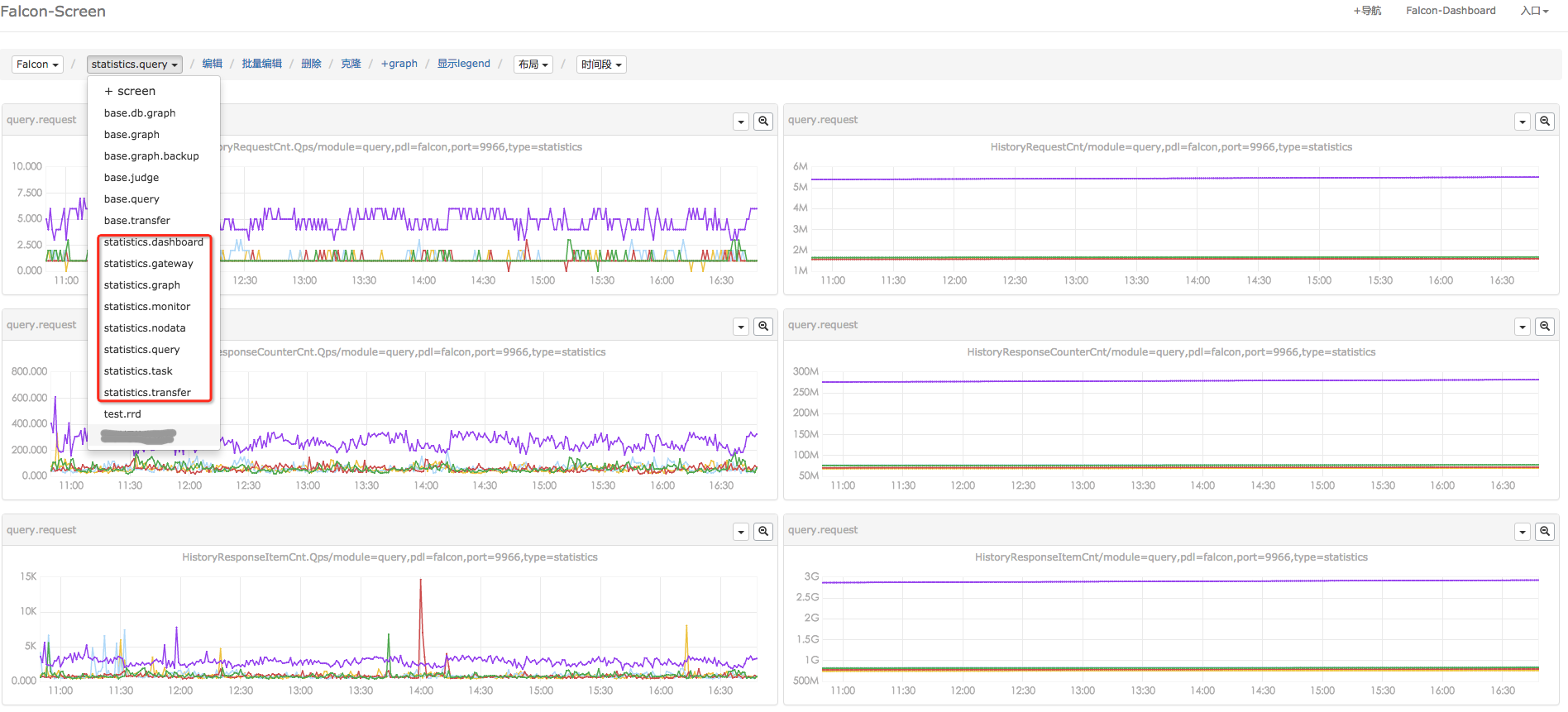
有了Open-Falcon自身状态数据的Screen,运维就会变得很方便: 每天早上开始正式工作之前,花10分钟时间看看这些历史曲线,小则发现已经发生的问题,大则预测故障、评估容量等。
1.4. 总结
对于自监控,简单整理下。
神医难自医。大型监控系统的故障监控,往往需要借助第三方监控系统(AntEye)。第三方监控系统,越简单、越独立,越好。
吃自己的狗粮。一个系统,充分暴露自身的状态数据,才更有利于维护。我们尽量,把状态数据的存储容器做成通用的、把获取状态数据的接口做成一致的、把状态数据的采集服务做成集中式的,方便继承、方便运维。当前,程序获取自己状态数据的过程还不太优雅、入侵严重;如果您能指点一二,我们将不胜感激。
1.5. 附录
1.5.1. 1. Open-Falcon状态指标
以下是Open-Falcon较重要的状态指标(非全部)及其含义。
## transfer
RecvCnt.Qps 接收数据的Qps
GraphSendCacheCnt 转发数据至Graph的缓存长度
SendToGraphCnt.Qps 转发数据至Graph的Qps
SendToGraphDropCnt.Qps 转发数据至Graph时, 由于缓存溢出而Drop数据的Qps
SendToGraphFailCnt.Qps 转发数据至Graph时, 发送数据失败的Qps
JudgeSendCacheCnt 转发数据至Judge的缓存长度
SendToJudgeCnt.Qps 转发数据至Judge的Qps
SendToJudgeDropCnt.Qps 转发数据至Judge时, 由于缓存溢出而Drop数据的Qps
SendToJudgeFailCnt.Qps 转发数据至Judge时, 发送数据失败的Qps
## graph
GraphRpcRecvCnt.Qps 接收数据的Qps
GraphQueryCnt.Qps 处理Query请求的Qps
GraphLastCnt.Qps 处理Last请求的Qps
IndexedItemCacheCnt 已缓存的索引数量,即监控指标数量
IndexUpdateAll 全量更新索引的次数
## query
HistoryRequestCnt.Qps 历史数据查询请求的Qps
HistoryResponseItemCnt.Qps 历史数据查询请求返回点数的Qps
LastRequestCnt.Qps Last查询请求的Qps
## task
CollectorCronCnt 自监控状态数据采集的次数
IndexDeleteCnt 索引垃圾清除的次数
IndexUpdateCnt 索引全量更新的次数
## gateway
RecvCnt.Qps 接收数据的Qps
SendCnt.Qps 发送数据至transfer的Qps
SendDropCnt.Qps 发送数据至transfer时,由于缓存溢出而Drop数据的Qps
SendFailCnt.Qps 发送数据至transfer时,发送失败的Qps
SendQueuesCnt 发送数据至transfer时,发送缓存的长度
## anteye
MonitorCronCnt 自监控进行状态判断的总次数
MonitorAlarmMailCnt 自监控报警发送邮件的次数
MonitorAlarmSmsCnt 自监控报警发送短信的次数
MonitorAlarmCallbackCnt 自监控报警调用callback的次数
## nodata
FloodRate nodata发生的百分比
CollectorCronCnt 数据采集的次数
JudgeCronCnt nodata判断的次数
NdConfigCronCnt 拉取nodata配置的次数
SenderCnt.Qps 发送模拟数据的Qps