1. Deployment Practice
This chapter introduces some of Xiaomi's actual practice of Open-Falcon deployment and also quantitatively analyse the features of every module of Open-Falcon.
1.1. Summary
Open-Falcon consists of basic modules, graph link and alarm link. Xiaomi's architecture of Open-Falcon deployment is shown in the picture below:
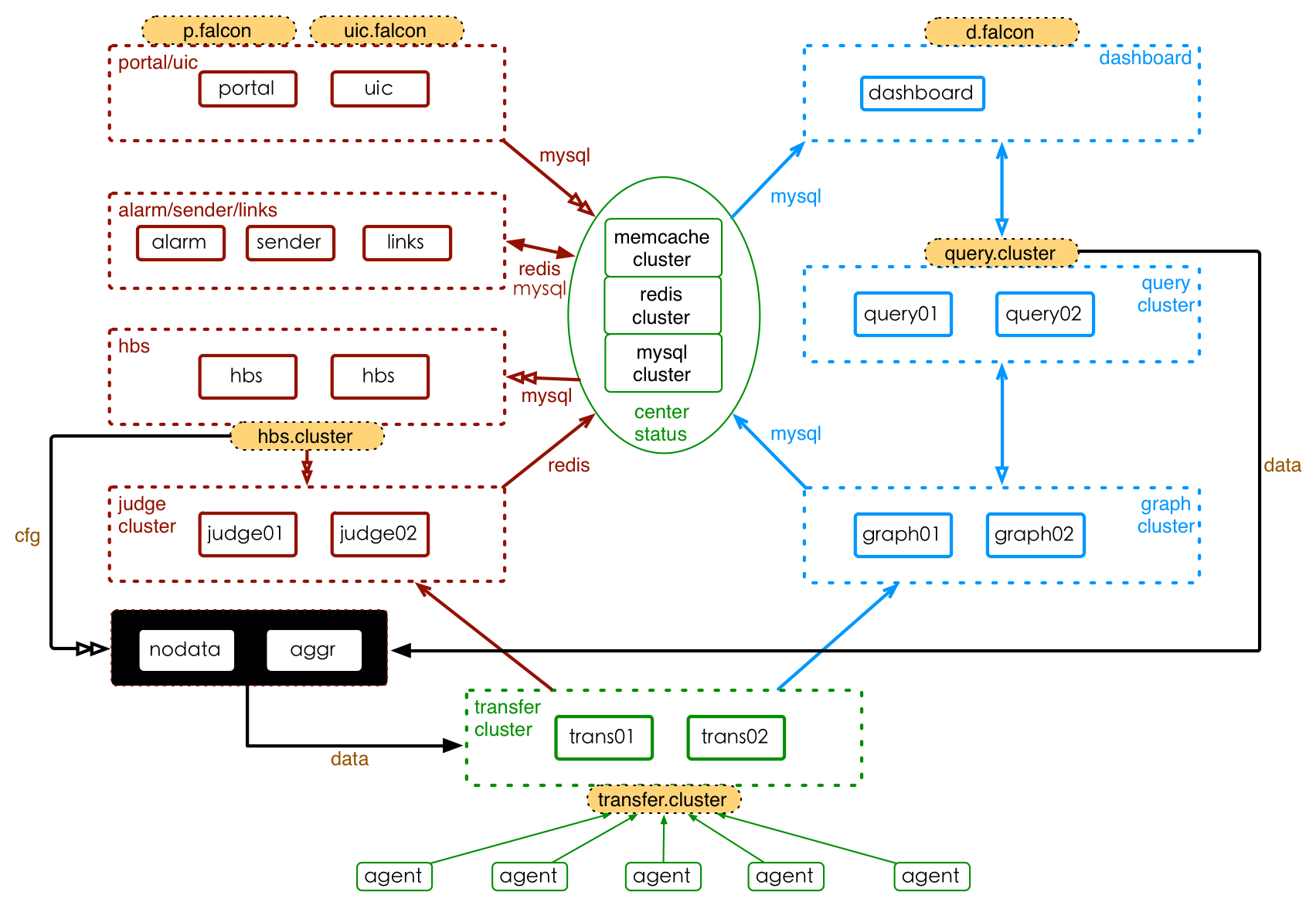
In the picture, basic modules are marked with green lines, graph link with blue lines and alarm link with red lines. And the modules filled with orange are domain names. Every module (sub service) has its own feature that the deployment strategy is based on. Next, we will do a qualitative analysis of the deployment evolution in plain language before we do quantitative analysis and give some advice.
1.2. Deployment Evolutioin
The deployment Open-Falon is evolving with the increasing number of machine (monitor object).
In the beginning of the stage, the number of machine is no more than 100. Basically users fon not have to worry about high availability because all the sub service can be deployed on one server altogether. One server with above average performance already meets the demand.
When the number reaches 500, graph may be the first that module that needs individual deployment, then Judge and transfer. Three are the most importmant modules of monitor system. Developers can sigh with relief when they are split into individuals.
When the number reaches 1,000, one instance in Graph, Judge and Transfer is not enough. Users are considering more than one instances being mixed and deployed with high availability. So all modules can be constructed in the multi-instance architecture with high availability except Alarm. The weakness of performance is more obvious as the number of machine keeps increasing. At least user can mitigate this problem by extending Open-Falcon horizontally.
Once the number of machine is over 10,000,it is our current situation. The system now collects data of more than 30 millions indexes. 20 instances are each deployed in Transfer and Graph, even 60 in Judge. (Three major modules are mixed and deployed on 20 high-performance servers and more than one instances are deployed in a machine of Judge.) Query and HBS each has 5 instances that are usually idle. Dashborad, Portal and Uic each has two instances. Although Alarm, Sender and Links surprisingly still has one instance. (The sub service of these module consume little resources so they are only deployed on about 10 low-performance machines.) The database of Graph is already separated with the database of Portal and UIC. Because the indexes of Graph already exceeds 50 million and it will endanger other subsystem if it is not separated. Redis is still in communion and has one instance. We keep improving the irrational part of out using plan.
One day the number will exceed 100,000。Sorry we have not experience this situation. We assume Graph index and HBS will become big issues. The system operation of Open-Falcon probably needs one person.
1.3. Basic Module
1.3.1. Agent
Agent is supposed to be deployed in every instance of the machine. Agent retrieves the configuration information from HBS, collects the data and report them to Transfer. Agent itself consumes little resources and it is reliable and stable. Xiaomi has deployed over 10,000 Agent instances and they have been running stably for over a year.
1.3.2. Transfer
Transfer is a stateless cluster. It receives data sent from Agent, slices them according to the consistent hashing algorithm and transfers the sliced data to Graph and Judge. Transfer also will print a copy of data to opentsdb.
Transfer cluster can be shrinked and expanded in some situation and the server can be immigrated sometimes. Those operations can effect the stability of Transfer cluster. If one Transfer instance stops working, it needs to be removed from the Transfer cluster. In order to eliminate the effect of removing a Transfer instance, we suggest users to attach a domain name to the Transfer cluster. Agent will visit Transfer cluster through the domain name, achieving automatic switching function. When there are several IDCs, we suggest users to deploy enough Transfer instances in each IDC and let Agent push the data to the Transfer of the IDC. User can configure the DNS rules to make the domain name of Transfer firstly be resolved as the Transfer instance of the local IDC.
The resources that Transfer consumes are mainly network and CPU. We run a test of performance on the Transfer installed in Dell-R620/Centos6.3. Dell-R620 has 24 cores and a 1000-Gb duplex network card. Here is the result.
| Incoming Data Speed | Outgoing Data Speed | Incoming Traffic | Outgoing Traffic | CPU Consumption (on average) |
|---|---|---|---|---|
| 50K piece/s | 100K piece/s | 180Mb/s | 370Mb/s | 300% |
| 100K piece/s | 200K piece/s | 360Mb/s | 740Mb/s | 620% |
Of course the test is performanced under ideal conditions and far from the resource limitation of the server. When the receiving end meets data peak value, its processing speed will slow down and many unsent data are stocked in the memory of Transfer. This will increase the memory consumption of Transfer. (In order to solve this problem, users can adjust the maximum cache limit to constrain the maximum memory consumption.) When users are evaluating the capacity of a Transfer cluster, they needs to take at least 100% redundance in to the consideration because of unbalanced data traffic, peak value and high availability. We would like to give you a configuration recommendation: incoming data speed of 10k piece/s, outgoing data speed of 20k piece/s, network card with no less than 100Mb and CPU no less than 100%.
1.3.3. Opentsdb
This function is complete. Welcome to the QQ group to exchange TSDB related experience.
1.3.4. Center-Status
Center-Status is the collective name for central storage. The storage Open-Falcon uses includes MySQL and Redis (Mencached is abandoned). MySQL is mainly used for saving index data and configuration information, like HostGroup, Alarm strategy, UIC information, Screen inforamtion. Redis is mainly used for alarm cache queue. Forming and querying the index happens frequently and they consume a lot of resources. So we suggest users to deploy an individual MySQL instance equipped with SSD hard disk when data monitor data reporting speed exceeds 100k piece/minute. One piece of meaningful data is: Graph index database, bin log enabled, saving 40 million counters, consecutively running for 60 days, 20GB of hard disk space is consumed.
Currently, our Mysql and Redis are deployed with one instance. So there is still an issue of high availability. The reading and writing of Mysql is still not separated as well as the database and list。
1.4. Graph Link
1.4.1. Graph
Graph module is used for saving and filing the data of diagrams. It can be deployed in cluster. Each Graph instance will process a slice of data. In other words, it will receive the sliced data sent by Transfer, file, save them and create an index. It will also process the query request from Query for this data.
Graph will consistently saving monitor data and writing them in the disk. Besides, the state data will be temporaryly saved in the memory. Therefore, the resources that Graph consumes are mainly hard disk space, hard disk IO and memory. We run a test of performance on the Graph installed in Dell-R620/Centos6.3 with an SSD of 2 TB" and here is the result:
| Collected Index Number | Storage Duration | DISK | Incoming Data Speed |
DISK.WIRTE REQUEST |
DISK.IO UTIL |
MEM |
|---|---|---|---|---|---|---|
| 900K | 5Y | 91GB | 4.42K/s | 1.6K/s | 3.0% | 5.2GB |
| 1800K | 5Y | 183GB | 8.78K/s | 3.2K/s | 7.9% | 10.0GB |
Of course the test is far from the resource limitation of the server. According to the result, we suggest user to deploy Graph on a server equipped with high-capacity hard disk and a big memory.Our recommendation is: the space of SSD hard disk is no less than 1GB and the memory is no less than 100M when 10k collected indexes are saved and the data traffic speed is over 100 piece/s; an index is save for 5 years cunsuming 100KB of the space of hard disk.
1.4.2. Query
It is inconvenient for users to query the data when they are sliced and saved in Graph. Query provides a standard port for data query and shield out the datails of data slicing. Query is mainly used in these two situations: displaying Dashboard diagrams and redeveloping the monitor data.
We suggest users to attach the query cluster to a domain for a better experience. At least two Query instances should to be deployed because of high availability.(Currently, IDC and rack where the two instances are deployed are responsible for high availability standard.) The detailed statistics of performance is still to be announced. The deployment practice in Xiaomi is 5 Queries provided the developers and operation staff all use Open-Falcon. (Actually two Querues is fairly enough.)
1.4.3. dashboard
Dashboard is used for displaying the diagrams of monitor data. It a a web application. Users does not read data for read diagrams that often in a monitor system. And they need less Queries and Dashboards. We suggest users to deploy more than two instances as web applications. The deployment practice in Xiaomi is 2 Dashboard instances provided the developers and operation staff all use Dashboard.
1.5. Alarm Link
1.5.1. Judge
Judge is designed for the triggerring logic of the alarm strategy. It can be deployed in cluster and each instance are assigned to process the sliced index data sent by Transfer. When Judge is calculating the logic, it will save the intermediate state and some history monitor data, so it will mainly consume memory and CPU. Here are the statistics.
| Collected Index Number | Alarm Strategy Number | MEM | CPU (on average) |
|---|---|---|---|
| 550K | xxx | 10GB | 100% |
| 1100K | xxx | 20GB | 200% |
The statistics are from the online Judge. According to the statistics, the consumption of memory and CPU shows a linear growth as the number of collected index number increases. Our recommendation is: 10K indexes consume 200MB of memory and 50% of CPU。One instance processes no more than 1,000 collected indexes.
1.5.2. HBS
HBS is the configuration center of Open-Falcon that is responsible for adapting the information of system configuration and managing Agent information. HBS deployment only needs one instance and each instance has complete configuration information. We suggest users to deploy more than two instances attached to HBS domain name with high availability, which is convenient for users.
Hbs consumes little resources. Here are Xiaomi's practice of deploying HBS for reference: 5 HBS instances are deployed with 10K Agent instances and 30 million indexes at the monitor data traffic speed of 150K/s; each HBS instance consumes 1GB of memory and less than 100% of CPU; the consumption of NET and DISK is neglectable.
The magnitude of data that these 5 HBS need to process is:
| host | hostGroup | hostGroup | express |
|---|---|---|---|
| 10K | 1.2K | 1.1K | 300 |
1.5.3. Portal
Portal the UI is relevant to monitor strategy management. It is not used very often and brings little loading to the machine. We suggest users to deploy more than two instances. The deployment practice in Xiaomi is 2 Portal instances provided the developers and operation staff all use Portal.
1.5.4. UIC
UIC is the management center of user's information, providing the UI that users manage. It is not used very often and brings little loading to the machine. We suggest users to deploy more than two instances as web applications. The deployment practice in Xiaomi is two instances for 360 users and 120 usergroups.
1.5.5. Alarm (Sender)
Alarm is responsible for filing alarm information to converse its format that is suitable for data sending. Alarm also does some work of combining alarms but it can only be deployed in one instance (which needs to be optimized). Since the amount of alarm information is quite small, the pressure of Alarm service is also very small, so one instance is fairly enough. We can only prepare a cold backup considering the the high availability. Sender is responsible for sending the final alarm content to users. Sender is stateless itself and can be deployed in several instances. Since the amount of alarm information is quite small, 2 sender instances are fairly enough for the needs of high availability and performance.
1.5.6. Links
Links are responsible for the display of alarms after they are combined. Links supports supports deployment in multi-instances and processing tasks that are relevant to alarm combination in slices. This service has little pressure and consume little resources. We suggest users to deploy 2 instances.
1.6. Mixed Deployment
Mixed deployment can improve resource utilization. First, we would like to summarize the feature of each sub service in Open-Falcon.
| Sub Service | MEM Consumption | CPU Consumption | DISK Consumption | NET Consumption | Main Resource |
|---|---|---|---|---|---|
| Agent | Low | Low | Low | Low | |
| Transfer | Low | Low | Neglectable | High | NET |
| Graph | Medium | Medium | High | Medium | DISK |
| Query | Low | Low | Neglectable | Medium | |
| Dashboard | Low | Low | Neglectable | Low | |
| Judge | High | Medium | Neglectable | Low | MEM |
| HBS | Medium | Medium | Neglectable | Low | |
| Portal | Low | Low | Neglectable | Low | |
| UIC | Low | Low | Neglectable | Low | |
| alarm | Low | Low | Neglectable | Low | |
| sender | Low | Low | Neglectable | Low | |
| links | Low | Low | Neglectable | Low |
According to these features and the damand of high availability, we can try some mixed deployments. Like:
- Transfer, Graph and Judge are the top three of Open-Falcon. They undertake the most pressure and consume the most resources, but they don't conflict with each other. We can consider deploying these three sub services on a high-performance server.
- Alarm, Sender and Links consume less resources but demand high stability. So we can choose to deploy them individually in a stable and low-performance machine.
- HBS consumes a consistent recource and it is not easily affected by external environment. So we can deploy itself in a low-performance machine.
- Dashboard, Portal and UIC are web applications, which cunsume less resources but are easily affected by user's operation. User can choose mixed deployment in low-performance machines and leave some margin.
- Query is easily affected by user's operation and its resource consumption is not stable. We suggest users to deploy itself on a low-performance machine with some margin.
1.7. Past Experience
- In order to improve the resource utilization, we once deployed several instances of the same sub service on one machine. It will significantly increase the difficulty of operation and probably require more labor force. So we figured out that low-performance machines can solve the problem of low resource utilization of one machine.